Blog posts
Collected posts from the various blogs I’ve contributed to since 2002.
Collected posts from the various blogs I’ve contributed to since 2002.
Contributing to the final day of the World Bank’s “Climate Smart Public Finance” conference in Cairo, Lauren Kahn and I presented some of what we’ve learned from the past decaces of digital transformation that can aid green transition. We looked at how starting small, scaling what works and building movements are as relevant to the daunting challenges of the green transition as they’ve been for successful digital initiatives. More on the event on the World Bank site ...

It was a pleasure to join Dr. Geeta Mazur, Digital Minister of Morroco; Gerardo Una from the IMF; and Amanda Walker for a discussion about inclusive growth and digital transformation at the 2023 IMF/World Bank annual meetings in Marrakech. We talked about the importance of thinking beyond technology to get to integrated views of change, the need for whole of government strategies (and good examples of those) but also the importance of not starting with everything. ...

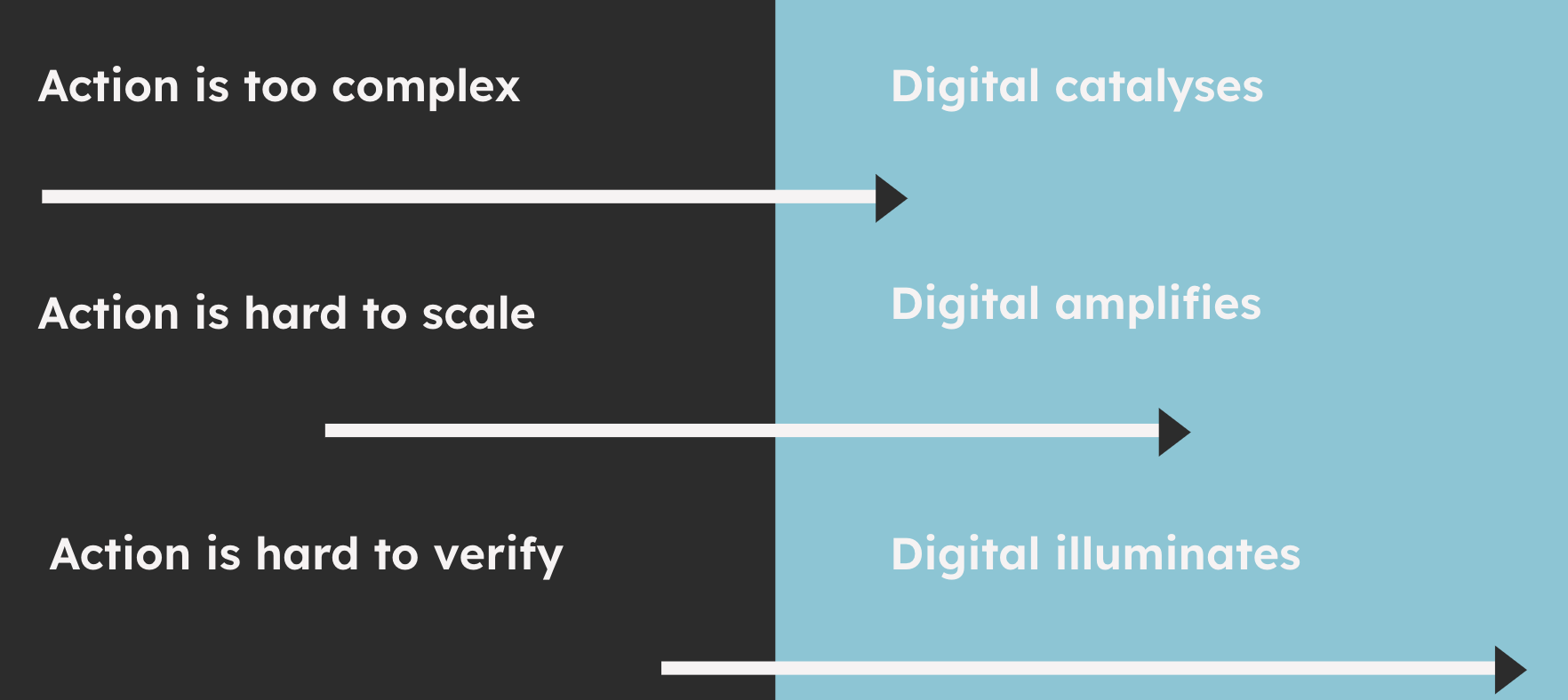
This article first appeared on the ODI website. As we prepare for our upcoming webinar on standards for fiscal data exchange, the team at the Digital Public Finance Hub has begun to reflect on how we think about data for fiscal policy formulation and implementation. In this instalment of Budgets and Bytes, James Stewart – a technologist from Public Digital – reflects on the promise and realities of data for fiscal policy, the traps we often fall into when trying to get better data, and how to break out of those traps. ...
This article first appeared on the Public Digital blog. Twice a year the leaders of international financial institutions and representatives of world governments are joined by a range of other attendees to set the priorities of two of the most important parts of the world economy: the International Monetary Fund (IMF) and the World Bank. Emily and I joined the Spring Meetings this year in Washington DC, taking the opportunity to meet with many of our friends, clients and collaborators. It was a pleasure to connect with those involved in our work on public finance reform, and others who are working on digital government initiatives that attract international finance. ...

I spoke to introduce and frame this inaugural event for the ODI and public digital Digital Public Finance Hub, presenting alongside Emily, Cathal and Marco to introduce some of the themes from our working papers on what we see as an emerging (and vital) paradigm for public financial management. Videos and other content from the event are available at ODI’s event website

Working with Cathal Long and Marco Cangiano at ODI, and Emily Middleton, Angie Kenny, and Joanne Esmyot at public digital I’ve been contributing to two papers laying out a new agenda for public financial management in the digital era. An emerging paradigm In the first paper in this series – entitled Digital public financial management: An emerging paradigm – we make the case that a paradigm shift is needed in how governments and development partners approach digital PFM. We outline an ‘emerging paradigm’ based on the latest thinking in PFM, digital change in government and digital technology. ...

Around the world there’s growing interest in Digital Public Infrastructure - the way that governments and societies can build strong digital foundations - and Digital Public Goods that help us share the best practices, standards and code that support it. Together these tools should help solve wicked societal problems like financial inclusion, public services, benefits, etc at scale and speed. Examples from India’s Aadhaar to the Open Banking standards that started in the UK to Brazil’s new payments systems have driven thinking about digital platforms and infrastructure to the top of the agenda of the G20 the UN and many other bodies. Viraj Tyagi of the eGov Foundation and James Stewart of Public Digital will discuss the developments they’re seeing, the importance of the agile community and how the community can connect with the work. ...

We’re growing used to talking about the importance of autonomous, high performing teams, and of bringing different technical disciplines together. But most organisations are more than their technology, and delivering great services requires organisations’ operations, policy, strategy and other functions to pull in the same direction. Drawing on experiences of bringing together teams across a broad range of disciplines in the UK and globally, James Stewart will look at why now is the time to really think multi-disciplinary and what some of the foundations are for much more inclusive digital work.) ...
This article first appeared on the Public Digital blog. One of our principles at Public Digital is starting small to go faster. This means delivering something quickly, even if this means on a smaller scale, so that you can identify its strengths and weaknesses at the earliest possible stage. It follows our approach that strategy is delivery, so implementation should begin early. Start with good enough, not perfect, and then get better before you scale up. ...
This article first appeared on the Public Digital blog. I was lucky to be able to attend the Code for America summit in Washington DC a couple of weeks ago. It was great to be able to gather with people in person after all this time, and reconnect with the community. The event felt diverse and exciting. That’s so important because after the past few years, everyone needs some fresh energy and to reconnect with a bigger vision. ...